After years of teaching concurrent programming across different contexts—systems programming with threads, hardware design with SystemVerilog, and GPU programming with CUDA—I watch students struggle with the exact same fundamental concept, just dressed up in different clothes.
It’s not syntax or APIs. It’s the deeper cognitive shift:
Abandoning the comfortable, sequential world where things happen one-after-another for the chaotic, parallel reality where everything happens at once.
The Sequential Mindset Trap
Most students arrive with what I call “recipe thinking”—the idea that programs are step-by-step instructions executed in order. This works beautifully for their first few years of programming. Variables get assigned, functions get called, loops iterate predictably. The computer does exactly what you tell it to do, when you tell it to do it.
Then we introduce concurrency, and the rules change.
In my systems classes, I show students a simple threading example—maybe two threads incrementing a shared counter. The code looks innocent enough, but when we run it, chaos ensues.

Race conditions appear. The final count is wrong, and worse, it’s inconsistently wrong. Students’ mental models shatter.
“But I told thread A to run first!” they protest. That’s the sequential mindset fighting back.
Three Faces of the Same Problem
What’s remarkable is how this same conceptual hurdle appears across completely different domains:
In systems programming, students struggle with the idea that std::thread() doesn’t mean “run this code now and then continue.” It means “start this other stream of execution that will run whenever the OS feels like scheduling it, possibly/probably at the same time as this code.”
In hardware design, the battle is even more fundamental. When I teach SystemVerilog, students want to treat modules like functions—call them with inputs, get outputs back, move to the next line. But hardware doesn’t work sequentially. When you describe a circuit, you’re describing a bunch of wires and gates that all exist simultaneously, all the time. Every clock edge, everything happens at once.
In GPU programming, students face the same wall again. They see parallel_for in our CUDA pseudocode and think “okay, so it’s like a regular for loop but faster.” Then they discover that thousands of threads are actually executing their loop body simultaneously, each with different data, each potentially taking different branches, each finishing at different times.
My Own Journey
Here’s where I wonder if I’m approaching this all wrong. When I first learned digital circuits in college, parallelism felt natural. You have gates, they have inputs and outputs, signals propagate through them simultaneously. A NAND gate doesn’t “wait” for an AND gate to finish1—they’re both just sitting there, doing their thing, all the time. The clock edge arrives and boom, everything happens at once across the entire circuit.
Maybe that early exposure to inherently parallel systems shaped how I think about computation. Maybe it was the scores of timing diagrams I filled in on problem sets and exams. Maybe that’s why I find it so frustrating when CS students take digital design thinking it’ll be “easier” than systems programming, only to hit the same wall from a different angle. They want to trace through circuits step-by-step like a program execution, and I’m over here trying to explain that there is no “step-by-step”—there’s just the steady-state behavior of a bunch of parallel logic.
The Teaching Challenge
The tricky part about teaching concurrency is that you can’t just throw more examples at the problem. Students don’t need to see more threading APIs or more CUDA syntax. They need to fundamentally rewire how they think about program execution.
Working with my professor, I’ve tried different approaches. Visual analogies with matrix multiplication where I show how each element calculation is independent. Color-coding threads in CUDA examples to make the parallelism explicit. Drawing those 3D grid-block-thread diagrams until my markers run dry at office hours.
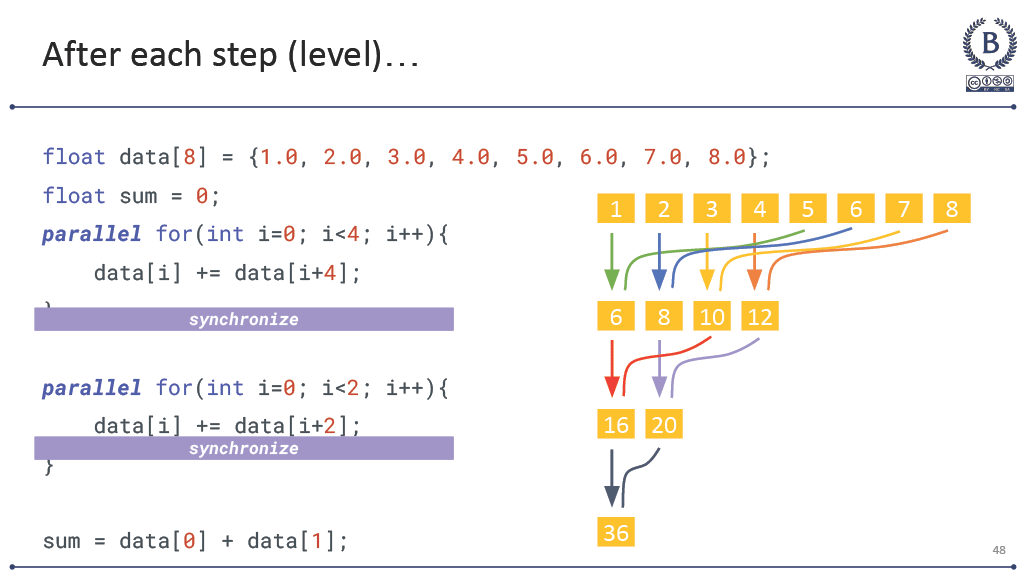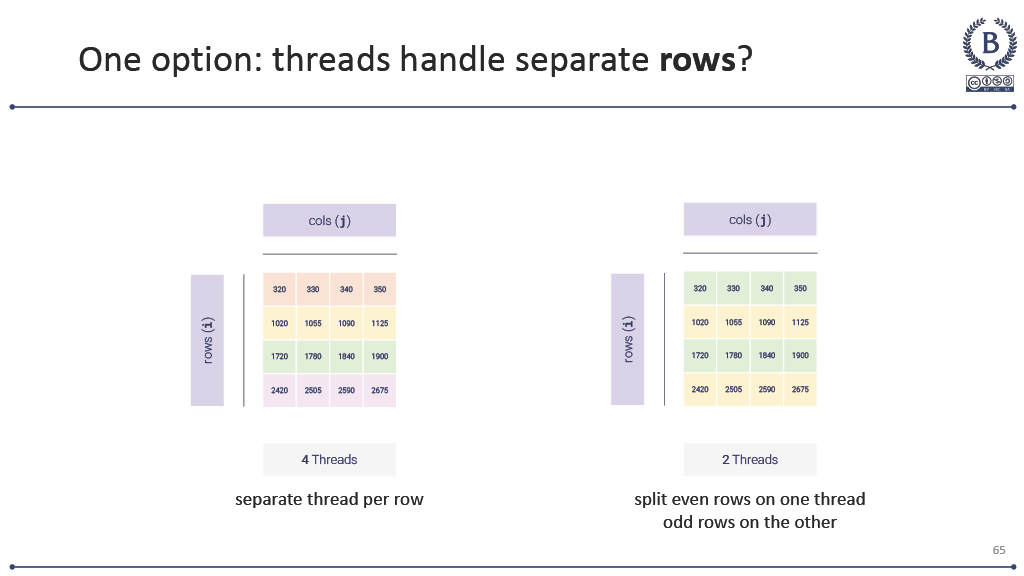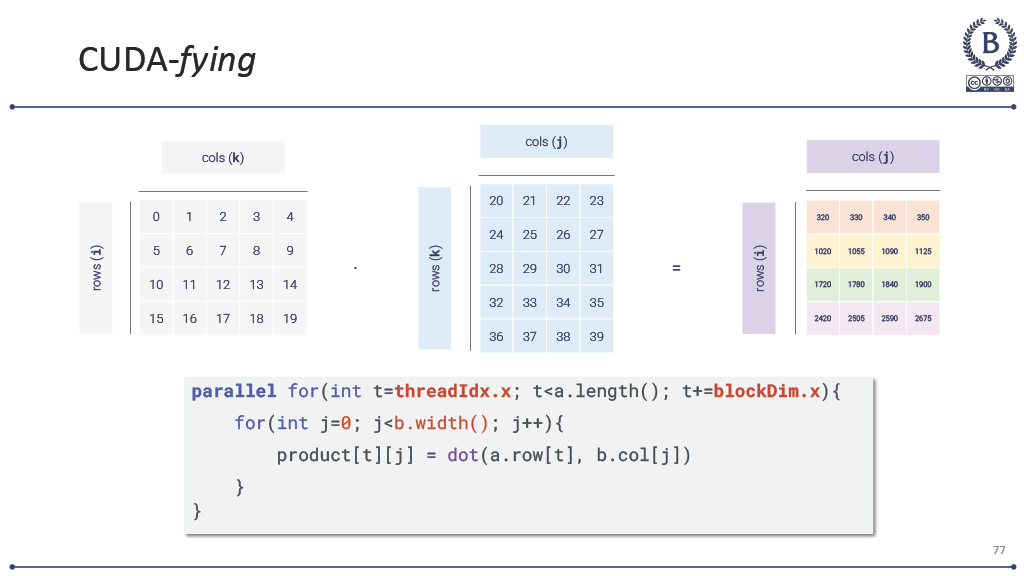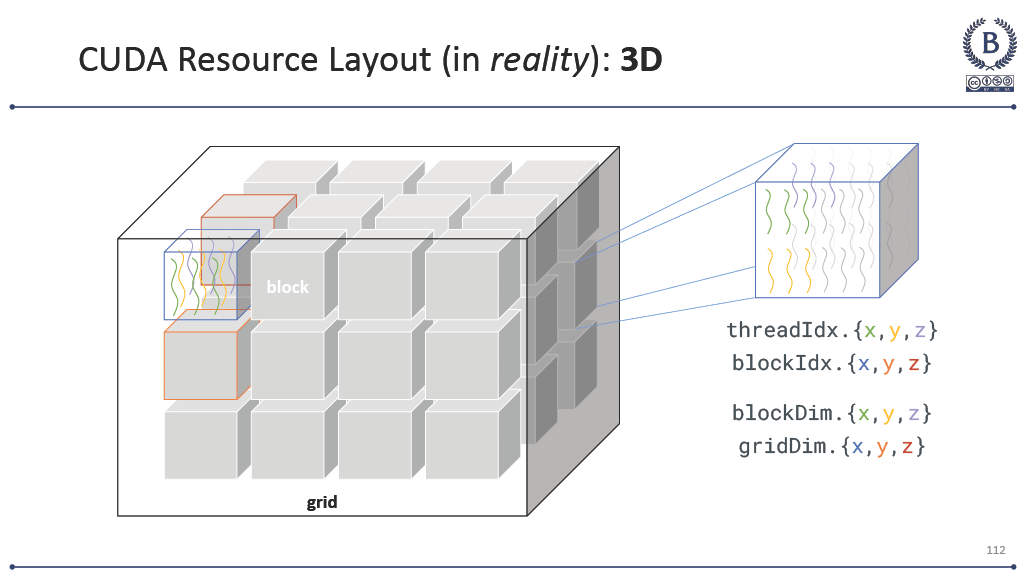
Sometimes a student will have what looks like a breakthrough moment—they’ll suddenly understand that blockDim.x threads are all running the same code simultaneously, or they’ll see why a race condition happens in their threading code. But then the next assignment reveals they’re still thinking sequentially underneath it all.
I want the key insight to be that:
Concurrent programming isn’t about making sequential programs run in parallel—it’s about recognizing the parallelism that was always lurking in the problem, then giving the hardware permission to exploit it.
But I’m not sure it lands.
I haven’t looked at canonical “concurrent programming” course materials yet because I keep hoping I’ll stumble onto some fresh approach that isn’t clouded by existing pedagogy. But maybe that’s naïve. Maybe there are established ways to help students make this mental transition that I’m just reinventing poorly.
The Persistent Mystery
What puzzles me most is the universality of the struggle. Whether it’s threads in C++, modules in SystemVerilog, or kernels in CUDA, students hit the same conceptual wall. They can learn the syntax, they can memorize the APIs, but that fundamental shift from “one thing after another” to “everything at once” remains elusive.
I see glimpses of understanding—moments where a student realizes that GPU threads aren’t like function calls, or that hardware description languages describe static circuits rather than sequential programs. But I can’t seem to reliably reproduce those moments or predict what triggers them.
The real challenge isn’t about threads or GPUs or hardware description languages. It’s about learning to think like the universe actually works: not one thing after another, but everything, all at once, all the time.
I’m just not sure how to get them there.
Footnotes
-
In reality, there are propagation delays and setup/hold times, sure, don’t get me wrong. But they’re still operating in parallel, causing glitches where timing constraints aren’t met. ↩
Comments